LLM Validation: Persona-Chat Accuracy on Crime Policy
Held-out variables: Urban unrest (1–7), death penalty (1–4), federal crime spending (1–5)
LLM: Claude Sonnet 4.5, temperature=0
Sample: 4,670 respondents (cluster methods); 200-respondent subsample (individual methods)
Uncertainty: Bootstrap 95% CIs (B=1,000) on individual models; sampling stability verified with 10 independent subsamples
What is being tested, and why it matters for the chat feature
Each AI persona on this site is grounded in real ANES 2024 survey data: its stances are
derived directly from its cluster's empirical profile across 49 policy questions.
But how faithfully does LLM reasoning actually reflect those ideological profiles?
To answer this, three crime-related questions were held out of the prompt entirely and
treated as prediction targets. The LLM was given a persona's remaining policy positions
and asked to predict how that voter would answer. If the predictions substantially
outperform random guessing, it means the reasoning process is picking up real ideological
signal, not just matching labels. The gap between cluster-level and individual-level methods
also reveals the cost of representing each respondent with a cluster average rather than
their own full profile.
All methods are benchmarked against random guessing (uniform distribution
over each response scale).
Prompt optimization:
Before running this validation, 22 prompt designs were tested systematically on a subset
of respondents, varying reasoning structure, framing, context, and representation style.
The best-performing cluster strategy (clean combo) and the next-best (modal) were selected
because no other variant beats them on both accuracy metrics simultaneously.
Baseline and CoT variants are included here for comparison despite being dominated by the clean combo.
Read the Prompt Optimization Report →
Six prediction methods compared:
-
(1) Cluster baseline: Cluster-level policy averages with 4-step internal
reasoning. 15 API calls, n=4,670. Dominated by (3) on both metrics.
-
(2) Cluster CoT: Same cluster input, but the model writes 2–3 sentences
of visible reasoning before the prediction. 15 API calls, n=4,670. Dominated by (3).
-
(3) Cluster clean combo ★: Combines (1)'s 4-step structure, (2)'s visible
CoT, and (4)'s modal instruction. Best overall within-±1 accuracy; not beaten on both
metrics simultaneously by any other variant. 15 API calls, n=4,670.
-
(4) Cluster modal: Model predicts the most common response in the cluster
rather than a mean. Highest exact-match rate but lower within-±1 than (3). Not dominated.
15 API calls, n=4,670.
-
(5) Individual: ideology only: Each respondent's own 46 non-crime policy
answers, no demographics. 200 API calls, n=200.
-
(6) Individual: ideology + demographics: Same as (5), plus gender, age,
education, and race/ethnicity. 200 API calls, n=200.
Key Findings
- All methods substantially beat random guessing on within-±1 accuracy.
Depending on scale width, random within-±1 ranges from 37% (urban unrest, 7-pt) to 61% (death penalty, 4-pt).
Every LLM method clears these bars by a wide margin, confirming that the persona framing
captures genuine ideological signal, not just label matching.
- Individual LLM models lead on exact match for most questions.
With access to each respondent's own 46-variable profile, the individual models achieve the
highest exact-match rates overall, most clearly on death penalty and urban unrest.
The gap is largest where within-cluster heterogeneity is highest.
- The clean combo (3) is the new best cluster strategy.
Combining the baseline's 4-step structure, CoT visible reasoning, and modal prediction
achieves 76.7% within-±1 and 32.5% exact match, dominating both the baseline (74.4%, 32.1%)
and CoT (76.1%, 30.6%) on both metrics simultaneously. Only modal (4) is non-dominated
alongside it, winning on exact match (35.9%) at a large within-±1 cost (64.7%).
The clean combo is recommended for deployment in the live chat feature.
- Cluster-level predictions are remarkably cost-efficient.
All four cluster strategies use just 15 API calls for all 4,670 respondents.
On within-±1, they are competitive with the individual models for death penalty and crime spending,
where ideological coherence within clusters is highest.
- Demographics add modest value at the individual level.
The CI ranges for models (5) and (6) overlap substantially. Urban unrest shows the clearest
improvement from adding gender, age, education, and race/ethnicity.
- Bootstrap uncertainty is real.
Individual model CIs span ~12–15 percentage points on exact match.
Point estimates alone are misleading; the ranges should be considered.
What this means for the chat feature
- The reasoning framing works: Even without access to individual profiles,
the cluster-level CoT prompt substantially outperforms random on all three crime questions,
confirming that the ideological grounding in cluster survey data translates into coherent predictions.
- Individual variation adds signal beyond clusters:
The individual LLM consistently improves over cluster methods on exact match, validating the
design choice to give each persona their own profile rather than just a cluster label.
- Prompt design matters at the cluster level:
A 15-call cluster experiment across 22 variants found that a clean combination of three
complementary ingredients (structured reasoning, visible CoT, and modal prediction)
dominates any single ingredient alone.
Results Overview
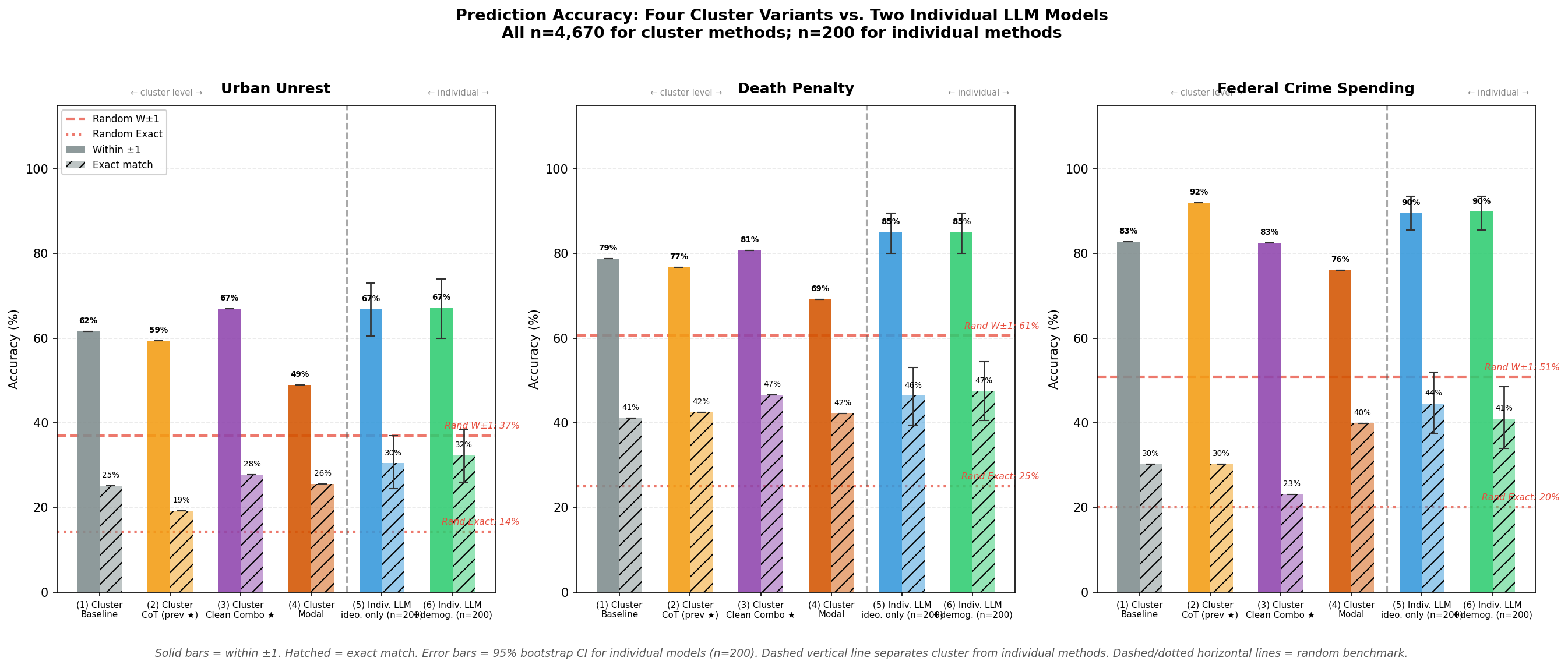
Solid bars = within ±1 accuracy. Hatched bars = exact match.
Red dashed/dotted lines = random benchmark (labeled per subplot).
Dashed vertical line separates cluster-level from individual-level methods.
Error bars = 95% bootstrap CIs for individual models (B=1,000 resamples).
Per-Question Results
| Question |
Random |
(1) Cluster
Baseline
n=4670 |
(2) Cluster
CoT (prev)
n=4670 |
(3) Cluster
Combo ★
n=4670 |
(4) Cluster
Modal
n=4670 |
(5) Indiv.
Ideo. only
n=200 [CI] |
(6) Indiv.
+Demog.
n=200 [CI] |
| Exact | W±1 |
Exact | W±1 |
Exact | W±1 |
Exact | W±1 |
Exact [CI] | W±1 [CI] |
Exact [CI] | W±1 [CI] |
Urban Unrest
1=solve racism/police violence ... 7=use all available force |
14.3% |
37.0% |
25.1% | 61.6% | 19.2% | 59.4% | 27.7% | 67.0% | 25.5% | 48.9% |
30.4%
[24.5–37.0] |
66.8%
[60.5–73.0] |
32.3%
[26.0–38.5] |
67.1%
[60.0–74.0] |
Death Penalty
1=favor strongly ... 4=oppose strongly |
25.0% |
60.6% |
41.0% | 78.8% | 42.5% | 76.8% | 46.7% | 80.7% | 42.2% | 69.2% |
46.4%
[39.5–53.0] |
84.9%
[80.0–89.5] |
47.4%
[40.5–54.5] |
85.0%
[80.0–89.5] |
Federal Crime Spending
1=increase a lot ... 5=decrease a lot |
20.0% |
50.8% |
30.2% | 82.8% | 30.2% | 92.1% | 23.1% | 82.5% | 39.8% | 76.0% |
44.5%
[37.5–52.0] |
89.6%
[85.5–93.5] |
41.0%
[34.0–48.5] |
89.9%
[85.5–93.5] |
Bootstrap CIs: B=1,000 resamples from the 200 individual LLM respondents.
Random benchmark: uniform prediction over each scale's integer range.
★ Clean Combo (3) is recommended for the live chat (dominates baseline and CoT on both metrics).
(3) and (4) are the only non-dominated cluster strategies in the two-way comparison
(exact match vs. within-±1). (1) and (2) are dominated by (3) but included for comparison.
Green/orange/red = thresholds: exact ≥40%/≥20%; within±1 ≥70%/≥50%.
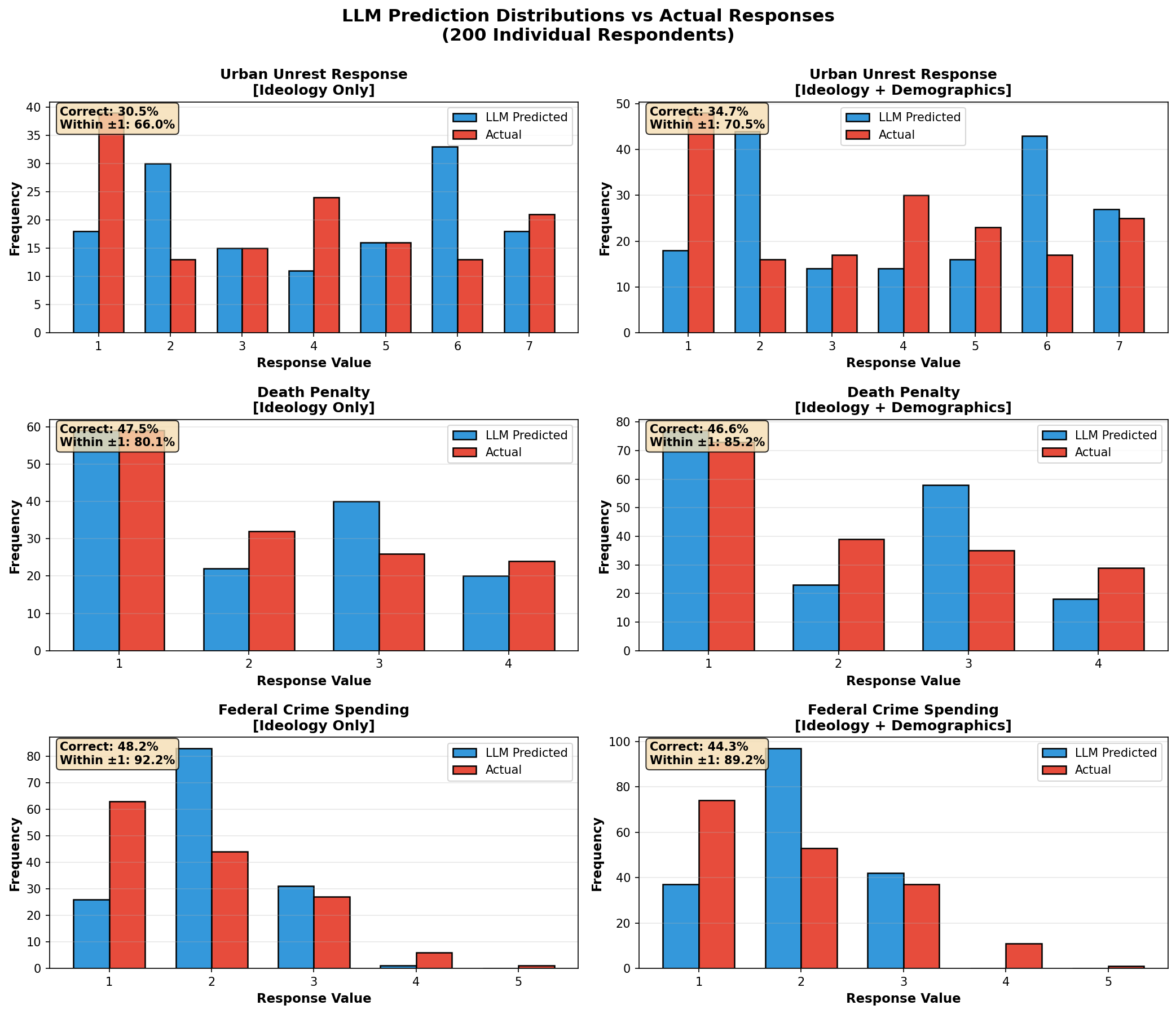
Response Distributions: All Methods
How to read: Red bars = actual ANES responses. Colored bars = predicted.
Each panel shows one method applied to one question.
Cluster methods cover all n=4,670; individual methods cover n=200.
Methodology
Held-Out Variables
V241397 Urban unrest (1=solve racism/police violence, 7=use all available force)V241308x Death penalty (1=favor strongly, 4=oppose strongly)V241272x Federal crime spending (1=increased a lot, 5=decreased a lot)
Cluster-Level Prompt Strategies
All four cluster strategies receive the same input (the cluster's mean policy positions
across 43 non-crime ANES variables) and differ only in how the LLM is instructed to reason:
- (1) Baseline: 4-step internal reasoning (select relevant positions → weight → form micro-profile → answer). Same prompt structure as the individual models. Dominated by (3).
- (2) CoT visible (previously deployed in chat): System instructs the model to write 2–3 sentences of reasoning before outputting JSON. Dominated by (3) on both metrics.
- (3) Clean combo (recommended): Combines (1)'s 4-step reasoning structure, (2)'s visible CoT, and (4)'s modal instruction. New best overall: 76.7% within-±1, 32.5% exact.
- (4) Modal prediction: System instructs the model to predict the most common (modal) response for each cluster, not a mean or average. Highest exact match (35.9%) but lowest within-±1 of cluster strategies (64.7%).
In a systematic experiment across 22 prompt variants,
strategies (3) and (4) are the only designs that no other variant beats on both metrics simultaneously
in the two-way comparison of exact match vs. within-±1.
Individual LLM Prompt Strategies and Bootstrap CIs
Both individual strategies use a 4-step internal reasoning prompt identical in structure to
cluster strategy (1). Input differs:
- (5) Ideology only: respondent's own answers to 46 non-crime policy questions.
- (6) Ideology + demographics: same, plus gender, age, education, race/ethnicity.
Because these models run on a 200-respondent subsample, their accuracy
estimates carry sampling uncertainty. The 200 respondents are resampled with replacement B=1,000 times;
the 2.5th and 97.5th percentiles of the bootstrap distribution form the 95% CI reported in the table.
Bootstrap CIs apply only to methods (5) and (6). Cluster methods cover all 4,670 respondents and
carry no sampling uncertainty.
Random Benchmark
Predictions are drawn uniformly from the integer scale range of each question (independent of
the respondent's actual responses). Exact-match rate = 1/K. Within-1 rate is computed from the
actual response distribution and scale endpoints.
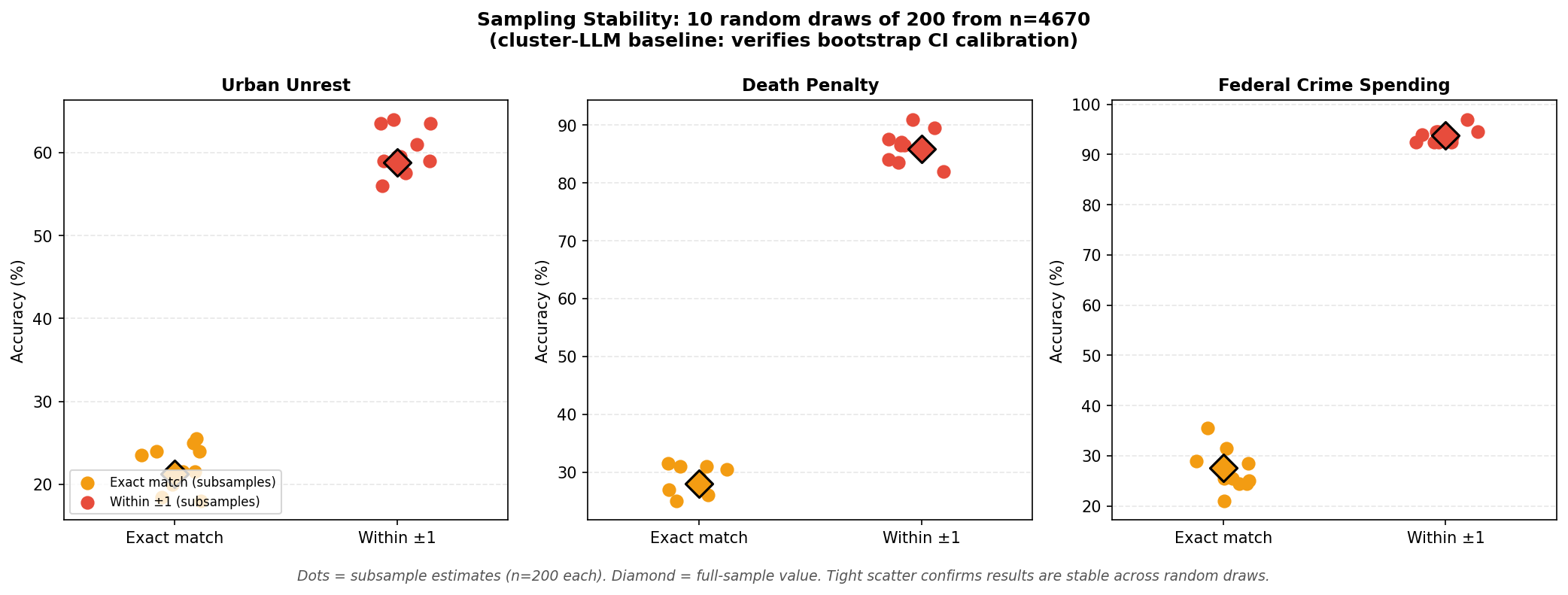
Sampling Stability (Individual LLM Only)
This section applies to the individual LLM methods (5) and (6) only. Because those models
run on a 200-respondent subsample, their accuracy estimates could vary across different draws.
To verify that 200 respondents is a stable enough sample size, the cluster-baseline (which is
deterministic and cheap to re-run) was applied to 10 independent random draws of 200 from the
full pool of 4,670. The resulting spread in accuracy estimates approximates the sampling
variability that would be observed for individual LLM methods, and can be compared against the
bootstrap CIs to check that the bootstrap is well-calibrated.
| Question |
Exact Match (%) |
Within ±1 (%) |
| Mean | SD | Range | Mean | SD | Range |
|---|
| Urban Unrest |
22.1% | 2.5% |
18.0%–25.5% |
60.2% | 2.6% |
56.0%–64.0% |
| Death Penalty |
28.6% | 2.2% |
25.0%–31.5% |
86.3% | 2.6% |
82.0%–91.0% |
| Federal Crime Spending |
27.1% | 3.9% |
21.0%–35.5% |
93.8% | 1.4% |
92.5%–97.0% |
Each row: cluster-baseline (method 1) accuracy on one random draw of 200 respondents from n=4,670. 10 draws total.
Raw Data
Enhanced results (bootstrap, cluster-LLM, subsampling): llm_validation_enhanced.json
Individual LLM results: llm_validation_individuals.json
Appendix A: Individual LLM Prompt (Respondent #1, Model C)
System message: "You are roleplaying as a real American voter from the 2024 ANES survey.
Answer crime policy questions in character as this voter would. Respond ONLY with the requested JSON."
You are roleplaying as respondent #1, a real American voter from the 2024 ANES survey. Based on the policy profile below, answer 3 crime-related survey questions exactly as this person would.
DEMOGRAPHICS:
- Gender: Woman
- Age in years: -3
- Education: Some college
- Race/ethnicity: White NH
POLICY POSITIONS:
- Party identity importance (1=extremely, 4=not at all)
Scale: 1 Extremely important; 2 Very important; 3 Moderately important; 4 A little important; 5 Not at all important
Response: 5
- Trust government in Washington (1=always, 5=never)
Scale: 1 Always; 2 Most of the time; 3 About half the time; 4 Some of the time; 5 Never
Response: 3
- Trust court system (1=always, 5=never)
Scale: 1 Always; 2 Most of the time; 3 About half the time; 4 Some of the time; 5 Never
Response: 3
- Gov run by few big interests or benefit of all (1=few interests, 2=benefit all)
Scale: 1 Run by a few big interests; 2 For the benefit of all the people
Response: 1
- Does government waste much tax money (1=waste lot, 4=don't waste much)
Scale: 1 Waste a lot; 2 Waste some; 3 Don’t waste very much
Response: 2
- How often can people be trusted (1=always, 5=never)
Scale: 1 Always; 2 Most of the time; 3 About half the time; 4 Some of the time; 5 Never
Response: 2
- Gov services/spending 7pt (1=fewer services, 7=more services)
Scale: 1 Government should provide many fewer services; 2–6 Intermediate positions on the scale; 7 Government should provide many more services; 99 Haven’t thought much about this
Response: 4
- Health insurance 7pt (1=gov plan, 7=private)
Scale: 1 Government insurance plan; 2–6 Intermediate positions on the scale; 7 Private insurance plan; 99 Haven’t thought much about this
Response: 6
- Abortion 7pt (1=always permit, 7=never permit)
Scale: 1 Abortion should always be permitted without restrictions; 2–6 Intermediate positions on the scale; 7 Abortion should never be permitted; 99 Haven’t thought much about this
Response: 5
- Guaranteed job/income 7pt (1=gov should, 7=people on own)
Scale: 1 Government should see to jobs and standard of living; 2–6 Intermediate positions on the scale; 7 Government should let each person get ahead on own; 99 Haven’t thought much about this
Response: 6
- Gov assistance to Blacks 7pt (1=help, 7=no special help)
Scale: 1 Government should help blacks; 2–6 Intermediate positions on the scale; 7 Blacks should help themselves; 99 Haven’t thought much about this
Response: 4
- Environment-business tradeoff 7pt (1=protect env, 7=business priority)
Scale: 1 Tougher regulations on business needed to protect environment; 2–6 Intermediate positions on the scale; 7 Regulations to protect environment already too much a burden on business; 99 Haven’t thought much about this
Response: 2
- Federal budget spending: Social Security
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Response: 3
- Federal budget spending: public schools
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Response: 3
- Federal budget spending: tightening border security
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Response: 2
- Federal budget spending: highways
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Response: 3
- Federal budget spending: aid to the poor
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Response: 3
- Federal budget spending: protecting the environment
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Response: 2
- Approve/disapprove how colleges and universities are run
Scale: 1 Approve very strongly; 2 Approve somewhat strongly; 3 Approve not very strongly; 4 Neither approve nor disapprove; 5 Disapprove not very strongly; 6 Disapprove somewhat strongly; 7 Disapprove strongly
Response: 6
- Approve/disapprove DEI (diversity, equity, inclusion)
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Response: 4
- Country better off if we just stayed home
Scale: 1 Agree strongly; 2 Agree somewhat; 3 Disagree somewhat; 4 Disagree strongly
Response: 4
- Use force to solve international problems (1=extremely willing, 7=extremely unwilling)
Scale: 1 Extremely willing; 2 Very willing; 3 Moderately willing; 4 A little willing; 5 Not at all willing
Response: 4
- Favor/oppose requiring ID when voting
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 1
- Favor/oppose allowing felons to vote
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 4
- Helpful/harmful if president didn't have to worry about Congress/courts
Scale: 1 Extremely helpful; 2 Moderately helpful; 3 A little helpful; 4 Neither helpful nor harmful; 5 A little harmful; 6 Moderately harmful; 7 Extremely harmful
Response: 6
- How much trust in news media (1=great deal, 5=none)
Scale: 1 None; 2 A little; 3 A moderate amount; 4 A lot; 5 A great deal
Response: 2
- Likelihood sexual harassment would keep you from voting for candidate (1=extremely, 5=not at all)
Scale: 1 Extremely likely; 2 Very likely; 3 Moderately likely; 4 Slightly likely; 5 Not likely at all
Response: 2
- How much larger is income gap today
Scale: 1 Much larger; 2 Somewhat larger; 3 About the same; 4 Somewhat smaller; 5 Much smaller
Response: 3
- Government action about rising temperatures
Scale: 1 Should be doing a great deal more; 2 Should be doing a moderate amount more; 3 Should be doing a little more; 4 Currently doing the right amount; 5 Should be doing a little less; 6 Should be doing a moderate amount less; 7 Should be doing a great deal less
Response: 2
- Require employers to offer paid leave to parents
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 5
- Approve/disapprove transgender bathroom use matching identity
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Response: 4
- Favor/oppose banning transgender girls from K-12 girls sports
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Response: 4
- Favor/oppose laws protecting gays/lesbians from job discrimination
Scale: 1 Favor strongly; 2 Favor not strongly; 3 Oppose not strongly; 4 Oppose strongly
Response: 4
- Should gay/lesbian couples be allowed to adopt children
Scale: 1 Feels very strongly should be permitted to adopt; 2 Feels somewhat strongly should be permitted to adopt; 3 Feels not strongly should be permitted to adopt; 4 Feels not strongly should not be permitted to adopt; 5 Feels somewhat strongly should not be permitted to adopt; 6 Feels very strongly should not be permitted to adopt
Response: 1
- Right of gay/lesbian couples to legally marry
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Response: 1
- Policy toward unauthorized immigrants (1=felony/deport, 5=no penalty)
Scale: 1 Make all unauthorized immigrants felons and send them back; 2 Guest worker program (remain to work for limited time); 3 Allow remain & qualify for citizenship if meet certain requirements; 4 Allow remain & qualify for citizenship without penalties
Response: 3
- Favor/oppose ending birthright citizenship
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 2
- Children brought illegally: send back or allow to stay
Scale: 1 Great deal sent back; 2 Moderate amount sent back; 3 A little sent back; 4 A little allowed to live & work in US; 5 Moderate amount allowed; 6 Great deal allowed
Response: 5
- Favor/oppose building wall on border with Mexico
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 4
- How important to speak English in US (1=extremely, 5=not at all)
Scale: 1 Very important; 2 Somewhat important; 3 Not very important; 4 Not at all important
Response: 2
- Favor/oppose US giving weapons to help Ukraine fight Russia
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 2
- Favor/oppose US giving military assistance to Israel
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 4
- Favor/oppose US giving humanitarian aid to Palestinians
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Response: 4
- Side more with Israelis or Palestinians
Scale: 1 Side a lot with Israelis; 2 Side a moderate amount with Israelis; 3 Side a little with Israelis; 4 Side with both equally; 5 Side a little with Palestinians; 6 Side a moderate amount with Palestinians; 7 Side a lot with Palestinians; 8 Side with neither
Response: 4
- Approve/disapprove of protests against war in Gaza
Scale: 1 Approve a lot of protests; 2 Approve a moderate amount of protests; 3 Approve a little of protests; 4 Neither approve nor disapprove of protests; 5 Disapprove a little of protests; 6 Disapprove a moderate amount of protests; 7 Disapprove a lot of protests
Response: 4
INSTRUCTIONS:
Use this internal reasoning process before answering (do NOT include it in your output):
1. Select: identify 3-7 positions above that are directly or indirectly related to crime, policing, law enforcement, racial justice, or public safety.
2. Weight: assign each selected position a relevance weight: HIGH / MED / LOW based on conceptual closeness to crime policy.
3. Profile: in 1-2 sentences, summarize what these weighted positions imply about this person's stance on crime and policing.
4. Answer: respond using only that profile. Stay true to the data -- if positions are extreme, reflect that. Do not artificially moderate.
Now answer these 3 survey questions for this respondent:
1. Urban unrest: Best way to deal with urban unrest and rioting?
Scale: 1 Solve problems of racism and police violence; 2-6 Intermediate; 7 Use all available force to maintain law and order
2. Death penalty: Do you favor or oppose the death penalty for persons convicted of murder?
Scale: 1 Favor strongly; 2 Favor not strongly; 3 Oppose not strongly; 4 Oppose strongly
3. Crime spending: Should federal spending on dealing with crime be increased, decreased, or kept the same?
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Respond with ONLY a JSON object: {"urban_unrest": X, "death_penalty": Y, "crime_spending": Z}
where X, Y, Z are integers on the scales indicated above.
Ground truth:
Urban unrest=2,
Death penalty=3,
Crime spending=1
LLM prediction:
Urban unrest=4.0,
Death penalty=2.0,
Crime spending=3.0
Appendix B: Cluster-LLM Prompt, Clean Combo v22 (Cluster 0: Progressive Cosmopolitans)
System message: "You are roleplaying as a representative voter from a 2024 ANES cluster. First write 2-3 sentences of reasoning from this voter's perspective, then output the MODAL (most common) integer response, the single value most members would choose, not a mean. Output the JSON on a new line."
You are roleplaying as a representative voter from Cluster 0 (Progressive Cosmopolitans) in the 2024 American National Election Study. The values below are the average survey responses for all voters in this cluster. Answer 3 crime-related survey questions as this type of voter would.
CLUSTER DEMOGRAPHICS:
- Population share: 5.3%
- College-educated: 76%
AVERAGE POLICY POSITIONS:
- Party identity importance (1=extremely, 4=not at all)
Scale: 1 Extremely important; 2 Very important; 3 Moderately important; 4 A little important; 5 Not at all important
Cluster average: 2.51
- How often can people be trusted (1=always, 5=never)
Scale: 1 Always; 2 Most of the time; 3 About half the time; 4 Some of the time; 5 Never
Cluster average: 2.72
- Trust government in Washington (1=always, 5=never)
Scale: 1 Always; 2 Most of the time; 3 About half the time; 4 Some of the time; 5 Never
Cluster average: 2.94
- Trust court system (1=always, 5=never)
Scale: 1 Always; 2 Most of the time; 3 About half the time; 4 Some of the time; 5 Never
Cluster average: 3.04
- Gov run by few big interests or benefit of all (1=few interests, 2=benefit all)
Scale: 1 Run by a few big interests; 2 For the benefit of all the people
Cluster average: 1.29
- Abortion 7pt (1=always permit, 7=never permit)
Scale: 1 Abortion should always be permitted without restrictions; 2–6 Intermediate positions on the scale; 7 Abortion should never be permitted; 99 Haven’t thought much about this
Cluster average: 1.82
- Approve/disapprove DEI (diversity, equity, inclusion)
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Cluster average: 2.07
- Approve/disapprove transgender bathroom use matching identity
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Cluster average: 2.21
- Favor/oppose banning transgender girls from K-12 girls sports
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Cluster average: 4.62
- Favor/oppose laws protecting gays/lesbians from job discrimination
Scale: 1 Favor strongly; 2 Favor not strongly; 3 Oppose not strongly; 4 Oppose strongly
Cluster average: 1.07
- Should gay/lesbian couples be allowed to adopt children
Scale: 1 Feels very strongly should be permitted to adopt; 2 Feels somewhat strongly should be permitted to adopt; 3 Feels not strongly should be permitted to adopt; 4 Feels not strongly should not be permitted to adopt; 5 Feels somewhat strongly should not be permitted to adopt; 6 Feels very strongly should not be permitted to adopt
Cluster average: 1.39
- Right of gay/lesbian couples to legally marry
Scale: 1 Favor a great deal; 2 Favor a moderate amount; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose a moderate amount; 7 Oppose a great deal
Cluster average: 1.74
- Does government waste much tax money (1=waste lot, 4=don't waste much)
Scale: 1 Waste a lot; 2 Waste some; 3 Don’t waste very much
Cluster average: 1.51
- Gov services/spending 7pt (1=fewer services, 7=more services)
Scale: 1 Government should provide many fewer services; 2–6 Intermediate positions on the scale; 7 Government should provide many more services; 99 Haven’t thought much about this
Cluster average: 5.44
- Defense spending 7pt (1=decrease, 7=increase)
Scale: 1 Greatly decrease defense spending; 2–6 Intermediate positions on the scale; 7 Greatly increase defense spending; 99 Haven’t thought much about this
Cluster average: 5.13
- Health insurance 7pt (1=gov plan, 7=private)
Scale: 1 Government insurance plan; 2–6 Intermediate positions on the scale; 7 Private insurance plan; 99 Haven’t thought much about this
Cluster average: 2.92
- Federal budget spending: tightening border security
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Cluster average: 1.79
- Favor/oppose ending birthright citizenship
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 5.96
- Policy toward unauthorized immigrants (1=felony/deport, 5=no penalty)
Scale: 1 Make all unauthorized immigrants felons and send them back; 2 Guest worker program (remain to work for limited time); 3 Allow remain & qualify for citizenship if meet certain requirements; 4 Allow remain & qualify for citizenship without penalties
Cluster average: 3.00
- Children brought illegally: send back or allow to stay
Scale: 1 Great deal sent back; 2 Moderate amount sent back; 3 A little sent back; 4 A little allowed to live & work in US; 5 Moderate amount allowed; 6 Great deal allowed
Cluster average: 5.83
- Favor/oppose building wall on border with Mexico
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 4.78
- How important to speak English in US (1=extremely, 5=not at all)
Scale: 1 Very important; 2 Somewhat important; 3 Not very important; 4 Not at all important
Cluster average: 1.77
- Country better off if we just stayed home
Scale: 1 Agree strongly; 2 Agree somewhat; 3 Disagree somewhat; 4 Disagree strongly
Cluster average: 3.58
- Use force to solve international problems (1=extremely willing, 7=extremely unwilling)
Scale: 1 Extremely willing; 2 Very willing; 3 Moderately willing; 4 A little willing; 5 Not at all willing
Cluster average: 2.97
- Favor/oppose US giving weapons to help Ukraine fight Russia
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 1.99
- Government action about rising temperatures
Scale: 1 Should be doing a great deal more; 2 Should be doing a moderate amount more; 3 Should be doing a little more; 4 Currently doing the right amount; 5 Should be doing a little less; 6 Should be doing a moderate amount less; 7 Should be doing a great deal less
Cluster average: 1.40
- Federal budget spending: protecting the environment
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Cluster average: 1.33
- Environment-business tradeoff 7pt (1=protect env, 7=business priority)
Scale: 1 Tougher regulations on business needed to protect environment; 2–6 Intermediate positions on the scale; 7 Regulations to protect environment already too much a burden on business; 99 Haven’t thought much about this
Cluster average: 1.86
- Approve/disapprove how colleges and universities are run
Scale: 1 Approve very strongly; 2 Approve somewhat strongly; 3 Approve not very strongly; 4 Neither approve nor disapprove; 5 Disapprove not very strongly; 6 Disapprove somewhat strongly; 7 Disapprove strongly
Cluster average: 3.55
- Federal budget spending: public schools
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Cluster average: 1.29
- Favor/oppose requiring ID when voting
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 2.06
- Favor/oppose allowing felons to vote
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 1.99
- Helpful/harmful if president didn't have to worry about Congress/courts
Scale: 1 Extremely helpful; 2 Moderately helpful; 3 A little helpful; 4 Neither helpful nor harmful; 5 A little harmful; 6 Moderately harmful; 7 Extremely harmful
Cluster average: 5.00
- How much trust in news media (1=great deal, 5=none)
Scale: 1 None; 2 A little; 3 A moderate amount; 4 A lot; 5 A great deal
Cluster average: 3.13
- Likelihood sexual harassment would keep you from voting for candidate (1=extremely, 5=not at all)
Scale: 1 Extremely likely; 2 Very likely; 3 Moderately likely; 4 Slightly likely; 5 Not likely at all
Cluster average: 1.43
- Gov assistance to Blacks 7pt (1=help, 7=no special help)
Scale: 1 Government should help blacks; 2–6 Intermediate positions on the scale; 7 Blacks should help themselves; 99 Haven’t thought much about this
Cluster average: 2.49
- How much larger is income gap today
Scale: 1 Much larger; 2 Somewhat larger; 3 About the same; 4 Somewhat smaller; 5 Much smaller
Cluster average: 1.25
- Require employers to offer paid leave to parents
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 1.26
- Guaranteed job/income 7pt (1=gov should, 7=people on own)
Scale: 1 Government should see to jobs and standard of living; 2–6 Intermediate positions on the scale; 7 Government should let each person get ahead on own; 99 Haven’t thought much about this
Cluster average: 2.71
- Federal budget spending: Social Security
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Cluster average: 1.55
- Federal budget spending: highways
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Cluster average: 1.55
- Federal budget spending: aid to the poor
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Cluster average: 1.54
- Favor/oppose US giving military assistance to Israel
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 2.54
- Favor/oppose US giving humanitarian aid to Palestinians
Scale: 1 Favor a great deal; 2 Favor moderately; 3 Favor a little; 4 Neither favor nor oppose; 5 Oppose a little; 6 Oppose moderately; 7 Oppose a great deal
Cluster average: 1.56
- Side more with Israelis or Palestinians
Scale: 1 Side a lot with Israelis; 2 Side a moderate amount with Israelis; 3 Side a little with Israelis; 4 Side with both equally; 5 Side a little with Palestinians; 6 Side a moderate amount with Palestinians; 7 Side a lot with Palestinians; 8 Side with neither
Cluster average: 3.49
- Approve/disapprove of protests against war in Gaza
Scale: 1 Approve a lot of protests; 2 Approve a moderate amount of protests; 3 Approve a little of protests; 4 Neither approve nor disapprove of protests; 5 Disapprove a little of protests; 6 Disapprove a moderate amount of protests; 7 Disapprove a lot of protests
Cluster average: 3.91
INSTRUCTIONS:
Step 1 — Briefly explain (2-3 sentences from this voter's perspective) which positions predict this cluster's crime views and what they imply.
Step 2 — Predict the MODAL response (the single most common integer answer, not a mean or average). Stay true to the data — if positions are extreme, reflect that.
Survey questions:
1. Urban unrest: Best way to deal with urban unrest and rioting?
Scale: 1 Solve problems of racism and police violence; 2-6 Intermediate; 7 Use all available force to maintain law and order
2. Death penalty: Do you favor or oppose the death penalty for persons convicted of murder?
Scale: 1 Favor strongly; 2 Favor not strongly; 3 Oppose not strongly; 4 Oppose strongly
3. Crime spending: Should federal spending on dealing with crime be increased, decreased, or kept the same?
Scale: 1 Increased a lot; 2 Increased a little; 3 Kept the same; 4 Decreased a little; 5 Decreased a lot
Respond with reasoning first, then ONLY a JSON object: {"urban_unrest": X, "death_penalty": Y, "crime_spending": Z}
where X, Y, Z are integers on the scales above.